solr索引数据同步与备份
Solr作为一个搜索服务器,在并发搜索请求的场景下,可能一台服务器很容易就垮掉,这时我们可以通过使用分布式技术,设置多台Solr搜索服务器同时对外提供搜索服务,这样每台Solr搜索服务器搜索请求的压力可以大大减小,增强了每台服务器能够持续提供服务器的能力。然而,这时我们面临的问题有:
- 分布式中的每台服务器在线上要保证索引数据都能很好地的同步,使得每台搜索服务器的索引数据在一定可以承受的程度上保持一致性;
- 分布式中某台服务器宕机离线,人工干预重启后继续与集群中其它服务器索引数据保持一致,继续提供搜索服务;
- 分布式中某台服务器的索引数据,由于硬盘故障或人为原因无法提供搜索服务,需要一种数据恢复机制;
- 分布式中接受数据更新的更新服务器,在将索引更新传播到其他服务器上时,避免多台检索服务器同一时间占用大量网络带宽,从而影响了更新提供服务。
事实上,Solr框架在上面的几个方面都能做到不错的支持,具有很大的灵活性。基于上述的几个问题,我们来配置Solr分布式的Replication,并实践分布式复制和备份的功能。
分布式数据同步
针对数据量小,但是并发量大的检索需求,我们可以通过分布式部署solr,设置一台solr服务器作为数据更新服务器,设置多台solr服务器同时对外服务,在前端使用某些负载均衡软件过配置使得并发到达的搜索请求均匀地反向代理到Solr分布式中的每一台搜索服务器上。solr分布式集群架构如下如:
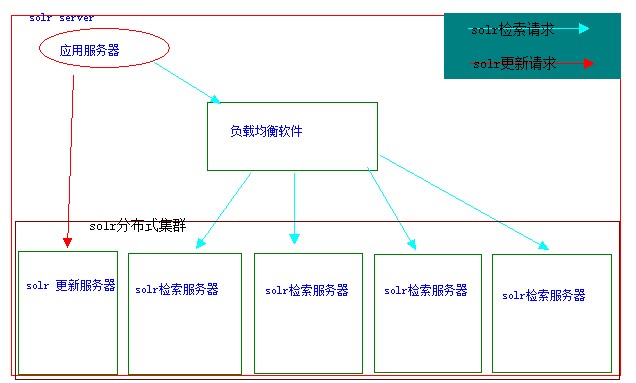
在分布式集群中当向solr更新服务器添加或更新索引后,在一定可以承受的程度范围内,solr分布式集群会将数据同步到检索服务器。这样就需要让solr检索服务器从solr更新服务器同步数据,这种同步模式的架构所示:
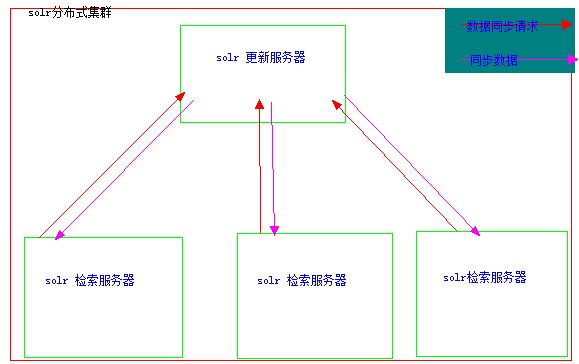
上图中,每台solr检索服务器会向solr更新服务器发起数据同步请求,当数据需要同步时,solr更新服务器会将需要同步的数据返回给solr检索服务器,这样每个solr检索服务器都可以最新的检索数据反馈给用户。
solr更新服务器作为检索数据的控制服务器(master),对应的solrconfig.xml的配置内容如下:
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<!--在提交和启动之后进行同步,可选择的项目还有'optimize(合并索引)' -->
<str name="replicateAfter">commit</str>
<str name="replicateAfter">startup</str>
<!--在提交和启动之后进行备份,可选择的项目还有'optimize(合并索引)' -->
<str name="backupAfter">startup</str>
<str name="backupAfter">commit</str>
<!--指定需要同步的配置文件,多份文件以逗号分隔 -->
<str name="confFiles">schema.xml,stopwords.txt</str>
<str name="commitReserveDuration">00:00:10</str>
</lst>
</requestHandler>
配置中name为/replication的requestHandler,即为Solr提供的复制请求处理接口,配置中replicateAfter表示在startup和commit之后才允许检索服务器的复制请求。
solr检索服务器作为检索数据的从服务器(Slave),对应的solrconfig.xml的配置内容如下:
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="slave">
<!--主索引的url,该从索引将从这个更新服务器地址同步索引-->
<str name="masterUrl">http://192.168.90.140:8990/solr/collection/replication</str>
<!--从主服务器同步索引的间隔时间,如果此项设置为空,将不主动从主服务器同步数据。可以通过admin页面或者http API触发同步动作-->
<str name="pollInterval">00:00:10</str>
<!--配置连接和读取超时时间,这个跟 http 中的概念一样,单位为毫秒-->
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<!-- 如果主服务中的 http base 的鉴权可用的话,从服务就需要配置这个用户名和密码 -->
<!--<str name="httpBasicAuthUser">username</str>
<str name="httpBasicAuthPassword">password</str>-->
</lst>
</requestHandler>
slave配置中masterUrl和pollInterval是必选的,masterUrl指定为索引数据的复制请求接口,pollInterval是指Slave周期地向Master询问是否数据有所更新,如果发生变更则进行复制。其它的参数可以根据需要进行配置。
通过上述的配置,当向更新服务器提交一条数据之后,检索服务器会将数据同步到本地。
通过上述可以看到,在只有一个更新服务器的Solr分布式集群中,如果存在大量的检索服务器要求同步数据,势必会造成对更新服务器的压力(网络带宽、系统IO、系统CPU),使更新服务器持续提供服务的能力降低,甚至宕机。Solr也考虑到这一点,通过在更新服务器和检索服务器之间建立一个代理的结点来改善单点故障,代理结点既同步更新服务器的数据,同时又将最新的数据同步复制到检索服务器结点,这个结点叫做中继服务器(Repeater),架构图如下:

由图可见,更新服务器的压力一下转移到了中继服务器上,在一定程度上解决了更新服务器的单点问题。对于中继服务器结点,它具有双重角色,显而易见,在配置的时候需要配置上Master和Slave都具有的属性。我们给出一个中继服务器的配置示例。
solr更新服务器配置:
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<!--在提交和启动之后进行同步,可选择的项目还有'optimize(合并索引)' -->
<str name="replicateAfter">commit</str>
<str name="replicateAfter">startup</str>
<!--在提交和启动之后进行备份,可选择的项目还有'optimize(合并索引)' -->
<str name="backupAfter">startup</str>
<str name="backupAfter">commit</str>
<!--指定需要同步的配置文件,多份文件以逗号分隔 -->
<str name="confFiles">schema.xml,stopwords.txt</str>
<!--同步数据的间隔时间,可根据提交索引的频率和网络数据进行调整,默认为10秒(从主服务器到从服务器同步5M数据大概需要10秒)-->
<str name="commitReserveDuration">00:00:10</str>
</lst>
</requestHandler>
solr中继服务器配置:
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<str name="replicateAfter">startup</str>
<str name="replicateAfter">commit</str>
<str name="commitReserveDuration">00:00:10</str>
</lst>
<lst name="slave">
<!--主索引的url,该从索引将从这个主索引地址同步索引-->
<str name="masterUrl">http://192.168.90.140:8990/solr/collection/replication</str>
<!--从主服务器同步索引的间隔时间,如果此项设置为空,将不主动从主服务器同步数据。可以通过admin页面或者http API触发同步动作-->
<str name="pollInterval">00:00:10</str>
<!--配置连接和读取超时时间,这个跟 http 中的概念一样,单位为毫秒-->
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<!-- 如果主服务中的 http base 的鉴权可用的话,从服务就需要配置这个用户名和密码 -->
<!--<str name="httpBasicAuthUser">username</str>
<str name="httpBasicAuthPassword">password</str>-->
</lst>
</requestHandler>
solr检索服务器配置:
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="slave">
<!--主索引的url,该从索引将从这个主索引地址同步索引-->
<str name="masterUrl">http://192.168.90.254:8990/solr/collection/replication</str>
<!--从主服务器同步索引的间隔时间,如果此项设置为空,将不主动从主服务器同步数据。可以通过admin页面或者http API触发同步动作-->
<str name="pollInterval">00:00:10</str>
<!--配置连接和读取超时时间,这个跟 http 中的概念一样,单位为毫秒-->
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<!-- 如果主服务中的 http base 的鉴权可用的话,从服务就需要配置这个用户名和密码 -->
<!--<str name="httpBasicAuthUser">username</str>
<str name="httpBasicAuthPassword">password</str>-->
</lst>
</requestHandler>
可见,Solr能够支持这种链式同步配置,甚至可以配置更多级,但具体如何配置还要依据你的应用的特点,以及资源条件的限制。总之,Solr目标就是让你系统的数据可用性变得更好。任何时候发生机器故障、硬盘故障、数据错误,都可以从其他的备机上同步数据。
单solr服务器数据备份
当如果没有部署solr分布式集群,只使用一台solr服务器提供服务时,对索引数据的备份将显得尤其重要。
在老版本的solr安装目录中存在一个复制索引数据的脚本,使用该脚本可以手动将索引数据备份下来,但是存在一个问题,当向服务器发起备份请求时,恰好应用服务器向solr发起了一个commit请求,solr服务器正在更新索引数据,这样就会造成备份与源数据的不同步。新版本的solr解决了该问题,删除了备份数据的脚本,提供了一个新式的备份数据功能,该功能其实就是运用了上述solr分布式集群中同步数据的功能。配置方式同上述分布式集群中的更新服务器配置。
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<!--在提交和启动之后进行备份,可选择的项目还有'optimize(合并索引)' -->
<str name="backupAfter">startup</str>
<str name="backupAfter">commit</str>
<!--指定需要同步的配置文件,多份文件以逗号分隔 -->
<str name="confFiles">schema.xml,stopwords.txt</str>
<str name="commitReserveDuration">00:00:10</str>
</lst>
</requestHandler>
将solr使用该配置并启动之后,可以定期通过http请求
http://ip:port/solr/collection/replication?command=backup&location=/opt/solr/solrDistributed 来对数据做备份,location参数的含义是将数据备份到/opt/solr/solrDistributed目录下,备份成功后会在该目录下存在名为snapshot.{时间数字串}的目录。如果索引数据损坏,只需要将备份数据复制到索引数据目录下即可。